在當今的舞臺燈光控制領域,一個顯著的趨勢是,許多應用場景已不再必須依賴傳統的大型專用硬件燈控臺。得益于計算機技術的飛速發展,功能強大、靈活多變的電腦軟件正逐步成為舞臺、演播室乃至小型活動現場燈光控制的主流選擇。這一轉變不僅降低了設備投入成本,也極大地提升了創意實現的自由度與工作流程的效率。本文將探討這一趨勢的背景,并概述電腦燈光控制軟件設計與開發的核心要點。
一、 趨勢背景:為何電腦軟件成為可行甚至優選方案?
- 硬件性能的普及:現代個人電腦,尤其是筆記本電腦,其計算能力、圖形處理能力和接口擴展性已足夠強大,能夠實時處理復雜的燈光場景數據、渲染可視化預覽并穩定輸出控制信號(如DMX、Art-Net、sACN等)。
- 成本與便攜性優勢:專業硬件燈控臺價格昂貴、體積龐大。而基于通用電腦的軟件解決方案,初始投入低,且便于攜帶和部署,特別適合巡演、臨時活動或預算有限的團隊。
- 集成與協作的便利性:軟件可以更容易地與音視頻播放、媒體服務器、時間碼同步系統等其他制作軟件集成,實現一體化的演出控制。它也便于通過網絡進行遠程監控和多用戶協作。
- 用戶界面與體驗的靈活性:軟件界面可以高度定制,適應不同用戶的操作習慣和不同規模項目的需求。觸摸屏、外接控臺、MIDI設備等都能與軟件結合,提供媲美甚至超越硬件的操控感。
- 更新與擴展的便捷性:軟件的功能可以通過版本更新持續迭代和增強,插件架構也允許用戶按需擴展支持新的燈具或特效。
二、 電腦燈光控制軟件的設計與開發要點
開發一款專業、可靠的電腦燈光控制軟件,需要綜合考慮多個關鍵領域:
1. 核心架構與穩定性
- 實時性引擎:軟件核心必須具備高優先級、低延遲的實時數據處理和輸出引擎,確保燈光指令的精準 timing,這是舞臺應用的性命攸關之處。
- 硬件抽象層:設計良好的硬件抽象層,以兼容多種DMX輸出接口(USB-DMX、以太網轉換器等)和網絡協議,確保控制的可靠性。
- 崩潰恢復機制:必須設計健全的自動保存和場景恢復機制,以防軟件或系統意外崩潰導致演出中斷。
2. 用戶界面(UI)與用戶體驗(UX)
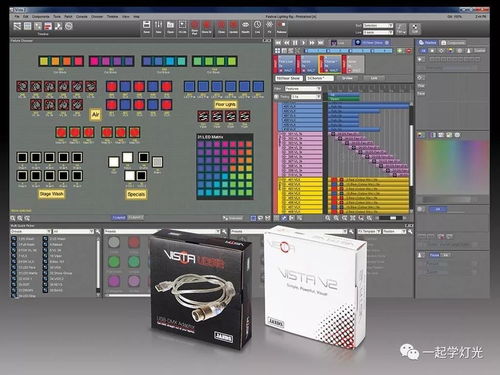
- 直觀的可視化:提供高質量的2D/3D可視化器,讓設計師能在編程和演出時實時預覽燈光效果,無需每次都實地亮燈。
- 高效的工作流:設計符合燈光設計師思維邏輯的編程流程,如cue列表管理、時間線編輯、素材庫、分組、顏色/圖案選擇器等,操作應力求高效、直觀。
- 多控模式支持:除了鼠標鍵盤,應支持觸摸屏優化、外接推子臺、MIDI控制器映射等,滿足現場“手感”操作需求。
3. 功能與協議支持
- 廣泛的燈具庫:內置并持續更新支持主流品牌和型號的燈具配置文件(Personality),并允許用戶自定義。
- 先進的控制功能:支持像素映射(Pixel Mapping)、媒體服務器控制(如MVR格式導入)、效果發生器、宏命令等高級功能。
- 網絡與協作:支持Art-Net、sACN等網絡傳輸協議,并可能集成多用戶編輯、遠程查看或備份控制等功能。
4. 開發技術考量
- 跨平臺性:考慮支持Windows、macOS甚至Linux系統,以覆蓋更廣泛的用戶群體。
- 性能優化:針對圖形渲染(可視化)、數據運算(效果生成)和I/O輸出進行深度優化,充分利用多核CPU和GPU資源。
- 安全與授權:實現合理的軟件許可機制,保護知識產權。
三、 應用場景與未來展望
電腦燈光控制軟件已廣泛應用于劇場、電視演播室、演唱會、商業活動、教堂、俱樂部以及沉浸式展覽等多種場景。對于中小型活動和固定安裝項目,其優勢尤為明顯。
隨著虛擬制作(XR)、實時渲染引擎(如Unreal Engine)與燈光控制的深度融合,軟件的定義和作用將更加核心。人工智能輔助編程、基于云端的協同設計與管理,也可能成為下一代軟件的新特性。
###
總而言之,“許多情形無須燈控臺,電腦軟件就行”并非一句空話,而是行業技術發展的真實寫照。對于開發者而言,深入理解燈光藝術與現場制作的需求,在穩定性、易用性和功能性之間找到最佳平衡,是打造成功軟件產品的關鍵。對于用戶而言,選擇合適的軟件,配以可靠的電腦和接口硬件,同樣能釋放無限的創意潛能,高效完成高質量的燈光制作。